Ideas Behind Responsive Emails
Chez CSS-Tricks, Chris Coyier présente les idées derrière les e-mails responsive, ou comment optimiser des e-mails pour mobile quand les applications ne supportent pas les media queries.
Chez CSS-Tricks, Chris Coyier présente les idées derrière les e-mails responsive, ou comment optimiser des e-mails pour mobile quand les applications ne supportent pas les media queries.
Rémi Grumeau a fait plein de tests sur différentes applications mails mobile pour savoir s’il y avait une différence lors de l’ajout d’une balise <meta name="viewport"> dans un e-mail.
Il y a quelques années, j’ai donné des cours d’intégration web dans une école supérieure de Lille. L’expérience fut particulièrement enrichissante, mais j’ai arrêté au bout de deux ans pour pas mal de raisons. Et parmi ces raisons, il y a le fait que je me suis rendu compte à l’époque qu’enseigner l’intégration, c’est incroyablement difficile.
Cela fait partie des sujets que j’ai abordés vendredi dernier lors de ma conférence à Sud Web. J’ai eu le droit à pas mal de questions, et notamment une de Delphine : est-ce que les cours que je donnais sont disponibles quelque part, et sinon quelles ressources utiliser pour enseigner l’intégration ?
Je me suis tout de suite revu me poser exactement cette deuxième question quelques années auparavant, malheureusement sans y trouver de réponse satisfaisante. Dans un milieu où le partage de nos savoirs est si important, il semblerait que les ressources de cours destinés aux débutants et orientés sur la qualité et les bonnes pratiques soient plutôt rares. Et c’est ainsi qu’est né l’envie d’animer un atelier avec Delphine le lendemain à Sud Web sur ce sujet : comment enseigner l’intégration web ? Romy nous a rejoint pour l’occasion, ainsi qu’une bonne vingtaine de participants pour en discuter pendant une heure et demie.
Voici un résumé des grands points que j’ai retenus de ces échanges :
Si cet atelier n’a abouti à rien de concret, il me fait beaucoup réfléchir, et me donne vraiment envie de chercher comment améliorer cette situation.
En attendant, j’aimerais beaucoup avoir les retours d’enseignants ou d’étudiants en intégration web. Comment enseignez-vous l’intégration web ? Ou comment avez-vous appris l’intégration web ? N’hésitez pas à partager vos réponses sur votre blog ou dans les commentaires ci-dessous…
Il y a du nouveau sur le webmail mobile de La Poste et son interprétation des media queries depuis mon précédent article. Mais ce n’est pas mieux pour autant.
Précédemment, je remarquais que le webmail mobile de La Poste supprimait systématiquement la première media query au sein d’une balise <style>, mais tout en conservant quand même les règles à l’intérieur de cette media query. J’ai remarqué cette semaine que ce problème avait été corrigé. La première media query n’est donc plus supprimée.
Mais, parce que forcément il y a un mais, celle-ci est désormais préfixée par le préfixe ajouté automatiquement par La Poste. Ainsi le code suivant…
.toto { background:red; }
.tutu { background:blue; }
@media only screen and (max-width:600px) {
.toto { background:white; }
.tutu { background:black; }
}
@media only screen and (min-width:320px) {
.toto { color:white; }
.tutu { color:black; }
}… sera transformé par le webmail mobile de La Poste en :
.wrapper_h8ufTw .toto { background:red; }
.wrapper_h8ufTw .tutu { background:blue; }
.wrapper_h8ufTw @media only screen and (max-width:600px) {
.toto { background:white; }
.wrapper_h8ufTw .tutu { background:black; }
.wrapper_h8ufTw }
@media only screen and (min-width:320px) {
.toto { color:white; }
.wrapper_h8ufTw .tutu { color:black; }
Autrement dit, les règles contenues dans la première media query ne fonctionneront pas sur le webmail mobile de La Poste. Pour palier à ça, ma recommandation du précédent article fonctionne toujours : ajoutez systématiquement une media query avec une règle factice avant vos vraies déclarations :
@media only screen and (max-width:0) {
body { margin:0; }
}Au passage, j’ai remarqué deux autres points sur l’interprétation des styles par le webmail mobile de La Poste :
Mozilla a sorti hier Firefox 29, avec plein de nouveautés, dont l’interface Australis présentée en août 2011. Pour l’occasion, la page d’atterrissage après téléchargement arbore un nouveau slogan : « Engagé pour vous, votre vie privée et le Web ouvert ».
Curieux de voir comment la page était construite (en particulier le guide interactif des nouvelles fonctionnalités), j’inspecte le code source. Et là, à ma grande surprise, je découvre que la page inclut le script de Google Analytics, et que tous les clics au sein de la page sont trackés, et les données envoyées à Google. Je relève cette contradiction avec le slogan de la page sur Twitter. Et rapidement, mon tweet est retweeté en grand nombre. Et @clochix aura la bonne idée de remonter cette incohérence sur Bugzilla.
Mais les réponses apportées par les membres de la communauté Mozilla seront à l’encontre de mes attentes. La discussion est très rapidement close, et on y explique que l’utilisation de Google Analytics fait partie de la politique de respect de la vie privée sur les sites de Mozilla. Chris More, responsable de l’équipe des sites de Mozilla, invite au téléchargement d’une extension pour bloquer Google Analytics. Et David Bruant, contributeur Mozilla, invite à poursuivre la discussion dans un groupe Google.
À ce stade, voici l’image qui me vient à l’esprit d’un Mozillien typique :

Le problème, ce n’est pas l’utilisation de Google Analytics. C’est un excellent outil, et je suis le premier à m’en servir, et à le proposer à mes clients. Par contre, je sais pertinemment qu’en utilisant ce service de Google, j’expose mes visiteurs à fournir un peu plus de données sur eux à Google, sans leur consentement.
Et puis pour être honnête, la décision d’utiliser Google Analytics chez Mozilla semble avoir été murement balancée, en désactivant notamment l’exploitation des données envoyées avec Google et ses tiers. Et l’inclusion du code de suivi en lui-même est aussi faite proprement, avec l’utilisation de la fonction _anonymizeIp() qui « supprime le dernier octet de l’adresse IP avant son stockage » chez Google.
Le problème, c’est, de mon point de vue, de se vanter de s’engager pour la privée de ses utilisateurs d’un côté, et d’avoir une relation de plus en plus dépendante à Google de l’autre. Parce qu’il ne s’agit pas que de Google Analytics. Mozilla dépends financièrement de Google. C’est une relation idyllique : Google paye Mozilla 300 millions de dollars par an, et Mozilla renvoie tous ses utilisateurs sur une recherche Google par défaut pour y cliquer sur des publicités AdWords. Sur le marché des navigateurs, Mozilla a pour mission de vendre du temps de cerveau disponible à Google en quelque sorte. Et Google, en terme de vie privée, c’est le mal absolu.
J’utilise des tas de services Google. Mais en les utilisant, je sais pertinemment que c’est au détriment de ma vie privée. Ainsi, je n’ai absolument aucune confiance en Google en ce qui concerne la protection de mes informations personnelles.
Alors pourquoi est-ce que je devrais faire confiance à Mozilla ?
Mozilla s’est construit en menant une lutte acharnée contre le monopole de Microsoft au début des années 2000. Ils ont fait un travail remarquable qui a permis d’arriver aujourd’hui à un marché et une concurrence saine entre les navigateurs desktop. Mais aujourd’hui, la société monopolistique qui fait peur à tout le monde, ce n’est plus Microsoft. Ce n’est pas Apple, qui n’a jamais eu le moindre monopole. Non, c’est Google, qui grâce à son monopole dans le domaine de la recherche, s’impose partout ailleurs.
Cette année, le contrat de trois ans signé entre Google et Mozilla en 2011 arrive à son terme. Nulle doute qu’il sera reconduit, pour un montant probablement encore plus élevé que le précédent (sachant que Google donne trois fois plus d’argent à Apple qu’à Mozilla pour être le moteur de recherche par défaut). Mozilla a le pouvoir incroyable de faire trembler le monopole de Google en refusant un nouvel accord. Mozilla pourrait alors être plus crédible à mes yeux pour parler de respect de vie privée.
Francisco Tolmasky, ancien développeur dans l’équipe de Safari sur iPhone chez Apple, raconte des anecdotes sur Steve Jobs :
M. Jobs était connu pour s’imposer autant qu’il le pouvait. Une personne de l’équipe de design de l’iPhone s’appelait aussi Steve, ce qui causait une certaine confusion dans les réunions. M. Jobs a cherché à changer ça.
« À un moment, Steve Jobs était vraiment frustré à cause de ça et a dit « Devine quoi, à partir de maintenant tu seras Margaret » », expliqua M. Tolmasky. À partir de ce moment là, les membres de l’équipe s’adressèrent à Steve le designer comme Margaret.
Autrement dit, Steve Jobs avait un petit côté Dr. Cox.
Jolie trouvaille vue cette semaine sur Twitter : l’application E-mail par défaut d’Android (aussi connue sous le nom de « pas Gmail, l’autre ») affiche le contenu de la balise <title> dans les notifications du système.
J’ai réussi à reproduire ce problème facilement sur une Nexus 7 sous Android 4.4.2. Cela ne concerne que cette application, et que l’affichage en notification. Ce texte n’est retrouvable nulle part ailleurs une fois dans l’application.
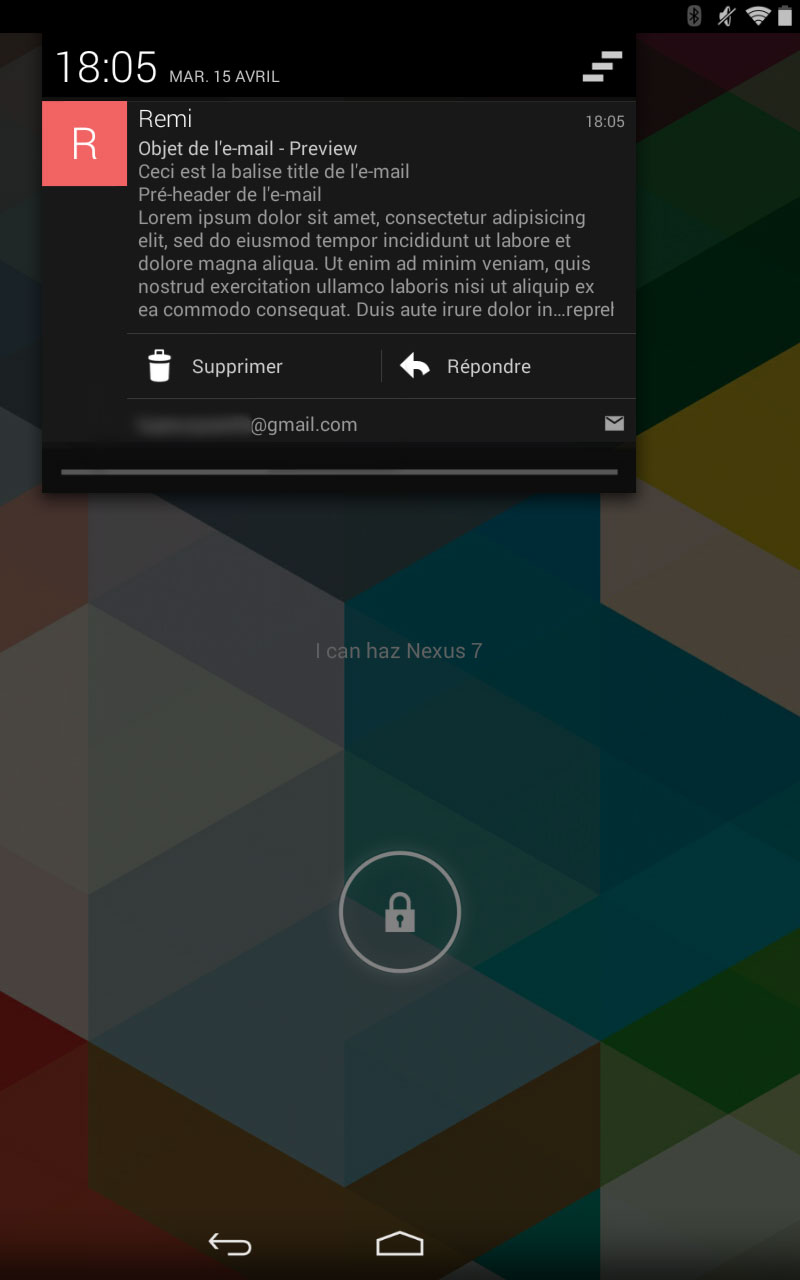
Veillez à avoir un contenu de <title> pertinent pour éviter d’afficher un « Document sans titre » ou « Responsive template ».
Cette semaine, j’ai eu la tristesse d’apprendre la fermeture de Five Simple Steps, un éditeur de sympathiques livres numériques sur la conception web. Ça m’embête d’autant plus que j’avais plein de leurs livres sur ma liste de choses à acheter un jour. Heureusement, certains auteurs ont déjà franchi le cap pour remettre à disposition leur livre ailleurs, et ce parfois désormais gratuitement. Voici une liste où trouver les titres initialement publiés par Five Simple Steps (bien aidé par la liste démarrée par Nick Bramwell et iTunes Link Maker).
A Pocket Guide
Practical Guides
Specials
Si vous repérez les quatre livres manquants, n’hésitez pas à me faire signe sur Twitter ou dans les commentaires.
Contrairement à d’autres webmails, la version classique d’Outlook.com ne se débrouille pas trop mal quand il s’agit de préfixer les règles CSS contenues dans un e-mail. Par défaut, toutes les règles CSS seront préfixées d’une classe .ExternalClass, et tous les noms de classes ou d’identifiants seront préfixés par ecx. Ainsi le code suivant :
.toto { background:red; }
.tutu { background:blue; }
@media only screen and (max-width:600px) {
table[class="toto"] { background:white; }
table[class="tutu"] { background:black; }
}… sera transformé en…
.ExternalClass .ecxtoto { background:red; }
.ExternalClass .ecxtutu { background:blue; }
@media only screen and (max-width:600px) {
.ExternalClass table[class="ecxtoto"] { background:white; }
.ExternalClass table[class="ecxtutu"] { background:black; }
}La classe .ExternalClass est alors judicieusement apposée sur une <div> contenant l’e-mail, et tout fonctionne comme si rien ne s’était passé. Jusqu’ici tout va bien, et on a presque envie de remercier les développeurs de chez Microsoft d’avoir fait correctement leur travail. Là où ça se gâte, c’est dans la version web mobile d’Outlook.com.
La version web mobile d’Outlook.com procède exactement au même renommage et préfixage des règles CSS que la version classique du webmail. Sauf que les développeurs ont oublié d’ajouter la classe .ExternalClass quelque part dans l’interface. Cela signifie que plus aucune de vos règles CSS n’est applicable. Si vous souhaitez optimiser des e-mails pour mobile pour Outlook.com, il est donc impératif de jouer uniquement avec des styles en ligne.
D’un coup, comme ça, on n’a plus tout à fait la même sympathie pour les développeurs de chez Microsoft.
Les statistiques des webmails et applications mail sont à prendre avec de très grosses pincettes. Quand vous tombez sur des infographies comme celle-ci ou celle-ci, il est important de comprendre comment ces données sont mesurées.
Pour mesurer son audience sur un site web, c’est facile. Il suffit d’installer un outil adéquat côté serveur (comme AWStats), ou d’utiliser un outil côté client (comme Google Analytics). Dans un e-mail, c’est plus compliqué car on ne peut ni accéder aux statistiques serveur de son fichier HTML une fois expédié, ni utiliser JavaScript. Ainsi, pour mesurer l’audience d’un e-mail, on va utiliser un mouchard, un fichier hébergé sur un serveur auquel on a accès, avec un ou plusieurs paramètres permettant d’enregistrer les informations qu’on souhaite obtenir. La plupart du temps, on utilise simplement une image.
Le problème de cette méthode, c’est qu’on va comptabiliser uniquement les webmails et applications mail affichant les images (par défaut, ou après une action utilisateur). Facebook utilise une balise <bgsound> en complément pour tenter d’atténuer le problème (notamment sur Outlook). Mais ce problème est particulièrement frappant quand on consulte des statistiques comme celles de Email Client Market Share, la petite page de données mises à jour par Litmus. Les trois versions d’Apple Mail, qui affiche par défaut les images, se retrouvent dans le top 5.

Et surtout, on remarque un bond spectaculaire dans l’utilisation de Gmail entre novembre 2013 (3,02 % de parts de marché) et janvier 2014 (9,5 % de parts de marché). L’explication est simple : en décembre 2013, Gmail a activé l’affichage des images par défaut.
En janvier 2014, le Journal du Net a publié un classement des webmails préférés des français (où par « préférés » ils voulaient surement dire « les plus utilisés »). On retrouve donc dans l’ordre le webmail d’Orange, Outlook.com, Gmail, SFR, Yahoo (suivis de, non cités dans l’article original, La Poste et Free). Ces chiffres viennent d’une étude Médiamétrie réalisée en novembre 2013. Pour obtenir ces chiffres, Médiamétrie a réalisé ce qu’ils appellent une «mesure panel». Ils ont recrutés 22 000 panélistes représentatifs de la population française, leur ont fait installé un logiciel enregistrant leur navigation web, puis ils ont traités et redressés les données. Cette méthodologie peut laisser perplexe quand à sa fiabilité, mais même s’il ne faut pas prendre ces chiffres pour argent comptant, ça permet quand même d’avoir une petite idée du marché français.
Sur la version mobile du webmail de La Poste, il y a un bug important dans leur analyse des styles, et plus particulièrement des media queries. Peu importe le contenu de votre balise <style>, la première media query sera toujours supprimée. Et pire, les règles à l’intérieur de cette media query seront conservées, sauf la première qui elle sera totalement ignorée.
Concrètement, cela signifie que le code suivant…
.toto { background:red; }
.tutu { background:blue; }
@media only screen and (max-width:600px) {
.toto { background:white; }
.tutu { background:black; }
}
@media only screen and (min-width:320px) {
.toto { color:white; }
.tutu { color:black; }
}… sera transformé par le webmail mobile de La Poste en :
.wrapper_h8ufTw .toto { background:red; }
.wrapper_h8ufTw .tutu { background:blue; }
.wrapper_h8ufTw .tutu { background:black; }
.wrapper_h8ufTw }
@media only screen and (min-width:320px) {
.toto { color:white; }
.wrapper_h8ufTw .tutu { color:black; }
.wrapper_h8ufTw }Cela peut s’avérer très problématique, car on se retrouve avec des règles appliquées par défaut alors qu’elles devaient l’être uniquement dans une media query. (Vous apprécierez au passage le préfixage buggé évoqué précédemment.)
Pour éviter cela, on peut insérer une première media query, en prenant le soin d’ajouter quand même à l’intérieur une règle (sinon la media query sera ignorée, et le bug quand même présent). Attention, comme ce bug est bien spécifique au webmail de La Poste, cela signifie que cette media query sera interprétée par d’autres applications ou webmails. Il est donc impératif d’ajouter un code bidon qui n’aura pas d’impact sur les autres. On peut par exemple cibler un max-width:0.
En reprenant le code de l’exemple initial, on obtient alors le code suivant :
.toto { background:red; }
.tutu { background:blue; }
@media only screen and (max-width:0) {
body { margin:0; }
}
@media only screen and (max-width:600px) {
.toto { background:white; }
.tutu { background:black; }
}
@media only screen and (min-width:320px) {
.toto { color:white; }
.tutu { color:black; }
}Le code final transformé par La Poste sera alors :
.wrapper_h8ufTw .toto { background:red; }
.wrapper_h8ufTw .tutu { background:blue; }
@media only screen and (max-width:600px) {
.toto { background:white; }
.wrapper_h8ufTw .tutu { background:black; }
.wrapper_h8ufTw }
@media only screen and (min-width:320px) {
.toto { color:white; }
.wrapper_h8ufTw .tutu { color:black; }
.wrapper_h8ufTw }Récemment j’ai enfin mis le doigt sur quelque chose qui me dérangeait depuis pas mal de temps, mais sans trop savoir pourquoi.
Il y a d’abord eu ce tweet de Charles de UXUI, dénonçant le site d’une agence qui publie sur son blog des traductions d’articles anglophones, mais sans jamais mentionner qu’il s’agit de traduction, en cachant discrètement l’article original sous un vulgaire lien « source », et en indiquant à la fin « article rédigé par [membre de leur équipe] ». Je trouve ça particulièrement malhonnête. C’est essayer de s’attribuer les mérites du travail d’un autre. Quelques échanges plus tard, la mention « article rédigé par » a été changée par « article mis en ligne par », ce qui est déjà un peu mieux. Mais il reste toujours ce vilain lien source.
Quand vous mettez un lien derrière un simple « via » ou « source », vous vous assurez que ce lien n’aura quasiment aucune valeur pour l’auteur, alors que ça aurait été l’occasion d’offrir à l’auteur à l’origine de votre propre publication un joli backlink.
Il n’y a rien de dévalorisant à citer quelqu’un. Si je lis quelqu’un que j’apprécie, et qu’en plus cette personne me fait découvrir de nouveaux auteurs à suivre, je n’en serais que plus reconnaissant. J’ai l’impression que les gens qui ne citent pas ou cachent leurs sources ont peur de perdre une partie de leur lectorat. Mais si c’est vraiment le cas, ça veut alors dire que votre article n’apporte strictement rien par rapport à l’article d’origine, et qu’il faut donc peut-être se remettre en question…
Et puis cette semaine, il y a eu ce classement des « développeurs francophones les plus suivis sur Twitter ». Je passe sur la pertinence de ce « concours de celui qui a la plus grosse », sur le fait que sur 50 développeurs, 36 ont des bios en anglais, ou sur la promotion spamesque faite pour cette page sur Twitter. Par contre, je suis plus dérangé par le fait que la raison principale de l’existence de cette page, c’est de faire la publicité des formations organisées par la société qui l’a créé. C’est certes discret, tout en bas de page, mais c’est bien là.
C’est en me tournant vers mon astrophysicien préféré que j’ai réussi à éclairer ce qui me dérangeait dans tout ça. Lors d’une rencontre avec Neil deGrasse Tyson dans son université, Anna H. a eu la chance de lui poser une question sur l’importance de la sensibilisation du grand public sur son métier.
Anna H : Vous parlez beaucoup du changement de la perception publique de la science. Je me demandais si vous pouviez nous parler des changements de la perception des scientifiques de la sensibilisation de leur métier — dans quelle mesure la sensibilisation est valorisée dans la communauté scientifique.
Neil deGrasse Tyson : Ah, excellente question, et une qui me tient particulièrement à coeur.
Carl Sagan a fait des erreurs, mais il était le premier a faire de la sensibilisation publique très visible, à grande échelle, donc il avait le droit de faire des erreurs. Mais je ne suis pas le premier, donc j’ai pu apprendre de ses erreurs. Carl ne donnait souvent pas crédit quand il décrivait des résultats de recherche astronomique. Beaucoup de gens regardant son programme ont pensé que c’était lui qui faisait toutes ces découvertes. Après son décès, des journaux ont écrit des choses comme « la seule récompense à lui avoir échappé était le prix Nobel ! », ce qu’ils n’auraient pu écrire que s’ils avaient pensé que toutes ces découvertes dont il parlait étaient ses découvertes. C’étaient des travaux sur lesquels d’autres scientifiques avaient peut-être passé des décennies, et Carl recevait toute la reconnaissance. Ça a rendu plein de gens amers.
Quand je décrit des recherches scientifiques, je fais toujours attention à les attribuer au groupe qui a travaillé sur le projet. Quand un journal m’appelle et me demande des commentaires, je les redirige toujours vers le groupe qui a fait le travail.
Aussi, je ne parle jamais de mes propres recherches. Je n’utilise pas ma plate-forme comme une opportunité pour faire la publicité de mes résultats personnels. Ma spécialité ce sont les galaxies, mais presque personne ne le sait. Je parle de ce qui selon moi va captiver le plus le public, et j’appelle des collègues si je n’y connais pas grand chose.
Je n’ai jamais ressenti d’antagonisme de la communauté professionnelle d’astronomie, et je pense que c’est parce que je leur donne toujours crédit pour leur travail.
Toujours donner crédit à ses sources, et ne jamais faire son auto-promo. Ce sont deux règles que j’essaye de suivre sans m’en rendre compte depuis des années.
La Poste, Orange, SFR et Voila ont la particularité d’être basé sur une même plate-forme de webmail, développée par Atos Wordline. C’est plutôt pratique, sauf que ça signifie qu’ils partagent aussi les mêmes bugs de cette plate-forme. Et en l’occurrence certains plutôt rigolos.
La plupart des webmails qui ne suppriment pas les balises <style> préfixent les règles CSS afin d’éviter tout conflit avec le reste de la page. C’est le cas de ces quatre webmails, qui préfixeront systématiquement les règles CSS par #message. Donc si vous écrivez une règle .toto, elle sera transformée en #message .toto.
Jusque là, c’est plutôt simple. Mais ça se complique quand on commence à utiliser des media queries. Dans une media query, le préfixe #message est toujours appliqué, sauf pour la première règle contenue à l’intérieur de cette media query. Ainsi l’exemple suivant…
.toto { background:red; }
.tutu { background:blue; }
@media only screen and (max-width:600px) {
.toto { background:white; }
.tutu { background:black; }
}… sera transformé en…
#message .toto { background:red; }
#message .tutu { background:blue; }
@media only screen and (max-width:600px) {
.toto { background:white; }
#message .tutu { background:black; }
}Cela signifie que la première règle .toto à l’intérieure de cette media query ne sera jamais interprétée, car elle est moins spécifique que la règle préfixée par #message au dessus. Pour palier à ça, il est alors impératif d’utiliser une règle !important à la fin de la première règle surchargée dans une media query. Dans l’exemple précédent, ça donnerait :
.toto { background:red; }
.tutu { background:blue; }
@media only screen and (max-width:600px) {
.toto { background:white !important; }
.tutu { background:black; }
}Là où ça devient rigolo, c’est quand on teste ça sur mobile. Parmi ces quatre webmails, La Poste est le seul à bénéficier d’une version optimisée pour mobile. Le comportement décrit précédemment est sensiblement le même, sauf que c’est une classe comportant un identifiant dynamique qui est utilisée, par exemple .wrapper_h8ufTw, au lieu de l’identifiant #message. Mais la particularité qui prête à sourire, c’est qu’à l’intérieure d’une media query, la dernière ligne correspondant à l’accolade de fermeture de cette media query est également préfixée. Dans des navigateurs modernes, ça n’a pas d’incidence sur le bon fonctionnement des règles. Mais ça donne le joli code transformé par le webmail suivant :
.wrapper_h8ufTw .toto { background:red; }
.wrapper_h8ufTw .tutu { background:blue; }
@media only screen and (max-width:600px) {
.toto { background:white !important; }
.wrapper_h8ufTw .tutu { background:black; }
.wrapper_h8ufTw }L’application Outlook.com sur Android affiche un extrait de l’e-mail dans les vues de liste d’e-mails. C’est plutôt pratique, sauf que contrairement aux autres applications qui font ça, le contenu affiché vient toujours de la version texte de l’e-mail (même si l’application est elle-même configurée par défaut pour afficher les e-mails en HTML).
Il faut donc bien veiller, lors du routage, à avoir le contenu souhaité en tout premier dans la version texte de l’e-mail.

Bonjour à tous ! J’ai le sentiment que l’intégration d’e-mails est une tâche conspuée, traitée comme un sous-domaine de l’intégration. Et pour cause : les applications mails et les webmails n’ont pas beaucoup évolué depuis le début des années 2000. Ou pire : ils ont évolué dans le mauvais sens.
Mais ce n’est pas une raison pour mal intégrer ses e-mails. Ce blog est une tentative d’expliquer le savoir-faire nécessaire à l’intégration d’e-mails, les horreurs obligatoires, les atrocités imposées par les webmails, … Mais aussi les choses qui m’amusent.
Jeremy Keith, sur son blog :
Cette idée d’un web comme une plate-forme, je la comprends d’un point de vue marketing. On aimerait utiliser cette phrase, parce qu’elle place le web à un pied d’égalité avec des véritables plate-formes.
Je dirais que Flash est une plate-forme, et native : iOS et Android et toutes ces choses. Ce sont des plate-formes, dans le sens où tout n’est qu’un gros paquet. Mais le web n’est pas comme ça.
Si vous utilisez la plate-forme Flash, n’importe qui ayant le plug-in Flash pourra accéder à votre contenu. C’est tout ou rien. C’est un ou zéro. C’est binaire. Soit ils ont la plate-forme, soit ils ne l’ont pas. Soit ils ont tout votre contenu, ou aucun de vos contenus.
Et c’est similaire avec les applications natives. Si vous avez le bon téléphone, vous pouvez avoir mon application. Toute mon application. Vous n’accédez pas à des morceaux de mon application, vous avez toute mon application. Ou vous n’avez rien du tout parce que vous n’avez pas ce téléphone spécifique que je supporte.
Le web n’est pas comme ça. Le web n’est pas binaire, un ou zéro, tout ou rien. Ce n’est pas une plate-forme où vous avez cent pour cent ou zéro pour cent. C’est un continuum.
La semaine dernière, le site Twitch a lancé Twitch Plays Pokemon. C’est grosso modo une version modifiée des jeux Pokémon Rouge et Bleu sur Game Boy contrôlée par les joueurs indiquant leurs commandes dans le chat. Ça donne un joyeux bordel où des milliers de joueurs indiquent toutes les commandes possibles et leurs contraires. Et aussi incroyable que ça puisse paraître, ils arrivent à progresser dans le jeu.
Le blog Minimaxir a publié un excellent compte-rendu de cette partie. Et plus particulièrement de certaines difficultés rencontrées :
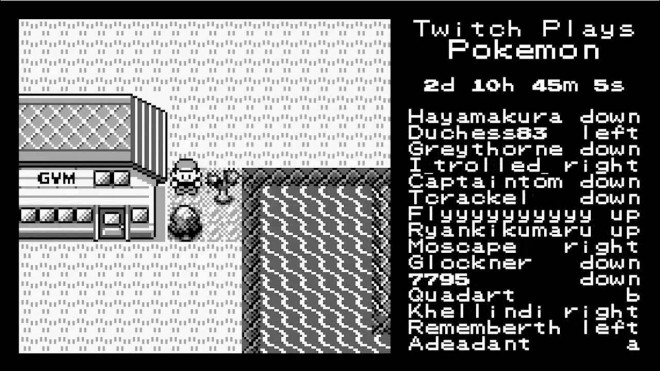
HM 01 est un objet qui permet de donner la capacité de Couper à un Pokémon, ce qui est nécessaire pour couper des arbres bloquant le passage. En l’occurrence ici, l’arbre en face du gymnase de Vermilion City. Afin d’apprendre à un Pokémon à couper, le joueur doit :
- Faire apparaître le menu Start.
- Sélectionner « Objets. »
- Sélectionner HM 01.
- Confirmer que HM 01 doit être utilisé.
- Choisir un Pokémon à qui apprendre à couper.
- Confirmer que le Pokémon choisi doit apprendre à couper.
- Choisir une capacité à remplacer par « couper ».
La partie marrante ? Appuyer sur le bouton B ou choisir la mauvaise option durant n’importe laquelle de ces sept étapes fait revenir le processus un pas en arrière.
À ce stade dans le flux, l’audience avait atteint 30 000 spectateurs. L’activité augmentée causait un délai d’entrée d’environ vingt secondes entre le moment où un utilisateur de Twitch avait saisi sa commande dans le chat et le moment où la commande était reconnue dans le jeu. Ça peut rendre la navigation dans les menus difficile quand une commande « Haut » ou « Bas » est appliquée à un menu qui n’est même pas encore visible.
En plus de ça, alors que le nombre de spectateurs augmentait, le nombre de trolls aussi. Et ces trolls adoraient spammer le bouton B.
Grâce à tous ces facteurs, la chaîne a passé plus de 4 heures sans parvenir à apprendre à un Pokémon à couper. Le chat était devenu un véritable bain se sang de reproches.
Et puis ça a fini par arriver. Le Canarticho a appris à couper. Personne ne sait comment, mais c’est arrivé. Mais ce n’était qu’un pas vers la progression.
La seconde étape était d’effectivement couper l’arbre en question. Afin de couper, il fallait
- Faire face à l’arbre.
- Faire apparaître le menu Start.
- Choisir « Pokémon ».
- Choisir le Pokémon avec qui couper.
- Choisir « Couper ».
Même problèmes qu’auparavant. Et faire face à l’arbre est encore plus difficile puisque les commandes Haut/Bas pour naviguer dans le menu peuvent éloigner le personnage de l’arbre.
Il a fallu à nouveau 4 heures pour couper cet arbre. Et plus tard, quand le personnage a été vaincu dans le gymnase, l’arbre avait réapparu. Oui.
HM 01 est un dur rappel que plus il y a de personnes présentes, plus il y a de chances que votre tâche échoue. Pas forcément à cause d’incompétence ou de manque d’organisation, mais simplement à cause de personnes mal intentionnées.
Cette avant dernière phrase s’applique particulièrement bien aux réunions en entreprise.
Un paragraphe dans l’introduction de l’article m’a particulièrement marqué :
Au final, la communauté des joueurs se bat contre son plus grand ennemi : soi même. Le but de Twitch Plays Pokémon n’est pas de gagner. C’est de ne pas échouer de manière spectaculaire. Et ils échouent quand même quoi qu’il en soit. C’est une irrésistible collision ferroviaire qu’il est difficile de s’arrêter de regarder.
Je trouve que ça fait une bonne analogie pour parler du web. Parce que quand j’y pense, c’est quand même incroyable que le web existe toujours et qu’on arrive à aller de l’avant dans cette plate-forme ouverte et collaborative. Parce que dans ce joyeux bordel, tout le monde aussi veut avoir le contrôle.
Entre les opérateurs (qui rêvent d’un web fermé où ils pourront facturer votre navigation par forfait de sites comme les abonnements TV), les fabricants de navigateurs (qui rêvent d’avoir un monopole absolu et d’imposer leurs technologies propriétaires), les États (qui rêvent d’avoir un contrôle sur tout ce qui peut transiter sur le réseau), et puis nous autres petits concepteurs web (qui rêvons d’avoir un contrôle sur le rendu et le fonctionnement de nos pages), c’est tout bonnement incroyable qu’on arrive à faire le moindre progrès.
Et pourtant.
J’aime bien les histoires de plagiat. Je me délecte toujours quand je lis des histoires comme celles de Marc Maggiori, des « Simpalas », de Layervault contre Flat UI, les documents internes de Samsung expliquant tout ce qu’il faut recopier d’iOS, ou des développeurs de Candy Crush Saga. Récemment, deux histoires m’ont particulièrement intéressé.
Tout d’abord, il y a l’histoire de Casey Neistat, un vidéaste américain, qui fin 2012 a eu l’idée de rendre une visite surprise à sa copine à l’autre bout du monde, et de filmer tout son périple au passage. Ça donne une vidéo sympathique bien qu’un peu longuette de son aventure très personnelle. Fin 2013, un français (cocorico) du nom de Maxime Barbier décide de reprendre le même concept, d’en faire sa vidéo, et de la vendre au passage à Coca-Cola. Maxime ne s’est pas caché d’être un fan de Casey Neistat et de s’être « inspiré » de sa vidéo, mais l’inspiration allait ici jusqu’à reprendre mot pour mot certaines répliques de la vidéo originale. Casey Neistat a donc publié un article sur son blog pour dénoncer tout ça, et la vidéo copiée a rapidement été retirée. Il explique ce qui le dérange le plus dans toute cette histoire :
C’est difficile de pointer du doigt pourquoi ça m’énerve autant. Copier fait partie du jeu. Ce n’est pas la première, et certainement pas la dernière, fois que quelque chose comme ça se produit. Peut-être que c’est parce que mon film était fait entièrement d’amour et de bonheur. Je ne faisais pas expressément un film, ce n’était pas la motivation pour surprendre ma copine. Je me suis juste retrouvé coincé dans des avions pendant 27 heures et j’ai décidé de tout filmer. Ce n’était que quelques semaines après le voyage que mon ami Max Joseph m’a aidé à monter le tout en un film après lui avoir montré les scènes de ma copine en train de crier quand elle m’a vu à sa porte à 12 000 Km de chez moi. Ou peut-être que c’est parce que je n’ai jamais gagné le moindre centime avec ma vidéo, que je n’avais même pas monétisée sur Youtube. C’est une histoire qui m’a rendu tellement heureux de la revivre encore et encore en regardant mon film que de regarder la copie merdique pour Coca-Cola de cet intrus a tout gâché pour moi.
Comme si cette expérience qui était si intime et centrale dans ma vie pouvait être reproduite et vendue en canettes rouges de trente-trois centilitres.
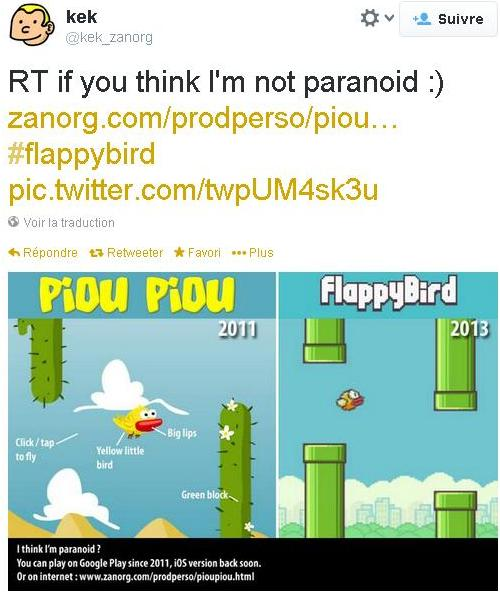
Plus récemment, Dong Nguyen, un développeur vietnamien, a connu un succès foudroyant avec un jeu sur iOS et Android : Flappy Bird. Sorti en milieu d’année dernière, le jeu était passé inaperçu. Mais après un mystérieux effet boule de neige et la mention sur une chaîne Youtube aux vingt millions d’abonnés, les téléchargements du jeu ont explosé. Le jeu rapporterait alors 50 000 dollars par jour en publicités à son créateur. Et c’est alors qu’entre en scène Kek, un autre français (cocorico), auteur habituellement de sympathiques bande-dessinées. D’après lui, Flappy Bird serait une copie pure et simple d’un de ses jeux, Piou Piou contre les cactus. Il contacte Dong Nguyen, qui nie avoir déjà entendu parlé de son jeu. Kek tente alors de faire la démonstration du plagiat sur Twitter en publiant l’image suivante :
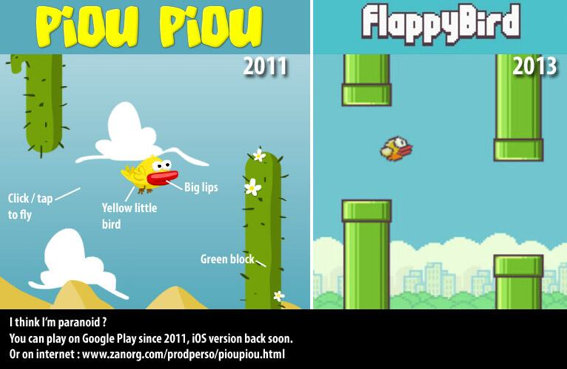
Et c’est là où ça commence à me déranger. Contrairement aux histoires de plagiat évidentes et avérées, ici Kek n’a aucun autre argument qu’une ressemblance entre les deux oiseaux. En réponse à certains détracteurs sur Twitter ou dans un article sur le Huffington Post, Kek estime être le créateur original du « petit oiseau jaune aux grosses lèvres ». Permettez-moi d’en douter. Au niveau du gameplay et de la réalisation, les deux jeux n’ont strictement rien à voir. Mais les deux jeux sont très inspirés de l’univers de Nintendo (les tuyaux pour Flappy Bird, les cactus et le désert pour Piou Piou). Mais ça suffit pour que le 8 février dernier, Dong Nguyen retire Flappy Bird de l’App Store et de Google Play, avec pour seul motif qu’il ne supporte plus le succès de son jeu. Et du coup, je ne peux pas m’empêcher de me poser la question : qu’attendait Kek en publiant cette image ? Est-ce que secrètement il espérait que l’auteur reconnaisse un plagiat, et lui verse un chèque ? Ou alors que l’auteur retire Flappy Bird pour que tout le monde se mette à jouer à Piou Piou (et tant pis si les deux jeux n’ont rien à voir, ludiquement parlant) ? Contrairement à la copie avérée de la vidéo de Casey Neistat, j’ai l’impression que la seule motivation du hurlement au plagiat ici est l’argent (ce qui ressent tout au long de la lecture de l’article de Kek, sobrement intitulé « Comment j’ai failli être millionnaire »).
Ça m’arrive aussi d’être copié. Parfois ce sont de simples tweets que je retrouve mots pour mots. Il y a quelques années, j’étais tombé sur un article ressemblant très fortement au mien sur l’e-mail le plus réussi au monde. Même sujet (pourtant assez spécifique et dont j’avais parlé pour des raisons personnelles évoquées en tout début d’article), et surtout, le « copieur » avait repris mot pour mot ma traduction de l’e-mail en question. Surpris mais amusé, j’avais posté les deux liens sur Twitter avec un message du genre « Copié / collé ». Ce que je n’avais pas prévu, c’est qu’en quelques minutes, le blog du copieur a été inondé de commentaires d’insultes, probablement de la part de certains de mes followers pas très malins. En voyant ça j’ai aussitôt supprimé mon tweet pour éviter d’autres commentaires nauséabonds. Mais le mal était fait. Plus tard, le copieur supprima son article. Je n’attendais rien de particulier en pointant du doigt cette copie. Mais au final, tout le monde a perdu : les lecteurs du blog copieur perdent un article intéressant, l’auteur du blog s’est fait insulté sans raison valable, et moi je me suis senti mal que tout ça arrive alors que je n’avais aucune attente particulière.
Et je crois que c’est ce qui me dérange dans l’histoire de Flappy Bird. Au final, tout le monde a perdu : les joueurs sont privés d’un jeu original, l’auteur a du retirer sa création personnelle, et Kek passe pour le méchant français avare de service.
La meilleure solution reste de prendre les plagiats comme des flatteries. Ou sinon, de ne plus rien créer du tout.
Je l’ai posté sur Twitter cette semaine, mais je le redis ici. Je trouve ce comparateur de portefeuille absolument génial.

Cette semaine, je suis tombé sur le site de Wired UK et cet article sur Tim Berners-Lee qui fait la une du numéro de mars. Et je suis resté jouer un petit moment avec la fonctionnalité d’agrandissement de l’image accompagnant l’article.

Quiz : à votre avis, en cliquant sur ce bouton « Enlarge« , que va-t-il se passer ?
Évidemment, c’est la réponse 2. Si c’est comme ça, c’est parce que sur des petites résolutions, l’image en question se trouve en haut de l’article. Sauf que sur mobile, l’agrandissement de l’image ne sert à rien puisque l’image prend déjà toute la largeur de l’écran.
Ou comment une fonctionnalité mal conçue en mobile first vient pourrir l’expérience desktop.
{kind=link}
{kind=link}
{kind=link}